
In today’s world of data warehousing, where businesses strive to unlock the full potential of their data, traditional approaches often need to be revised. The evolution of data modeling and the need for scalable, agile, and robust data solutions led to the emergence of Data Vault 2.0.
This blog will explore the Challenges of Enterprise Data Warehouse (EDW), the Overview of Data Vault 2.0, its key components, benefits, and why it has become a revolutionary approach to the fast-paced Data Warehousing Era.
Challenges for Enterprise Data Warehouse (EDW)
- Multiple business source systems –
When data comes from multiple business source systems with different structures, attributes & granularity, onboarding these systems in an iterative-prioritized manner fashion is complex and strenuous. - The only constant is change –
When the upstream business source systems and structures change frequently and fail to provide consistent data, even if there is a change to only one business system, that change can show up for only some other business source systems. - Increasing Data, Performance issues, and Multiple Teams involved –
Traditional data processing and modeling techniques may need to be revised to handle the sheer size of the data. Capturing, processing, transforming, cleansing, and reporting on this ever-growing data is overwhelming and requires a competitive technology edge. This becomes even more challenging when multiple teams work in parallel on the same Data Warehouse.
Challenges for Enterprise Data Warehouse (EDW)
Data Vault 2.0 is a data warehousing methodology that aims to provide agility, scalability & flexibility to store and integrate data. It was first introduced by Dan Linstedt in 2011 as an extension of the original Data Vault modeling technique. Data Vault 2.0 is designed to handle the ever-increasing volumes of data, complex business requirements, and changing data sources that organizations face today.
Bill Inmon, Father of Data Warehousing, stated for the record:
“The Data Vault is the optimal choice for modeling the EDW in the DW 2.0 framework.”
Let’s implement Data Vault 2.0
At its core, it is an iterative modeling approach that consists of three types of tables:
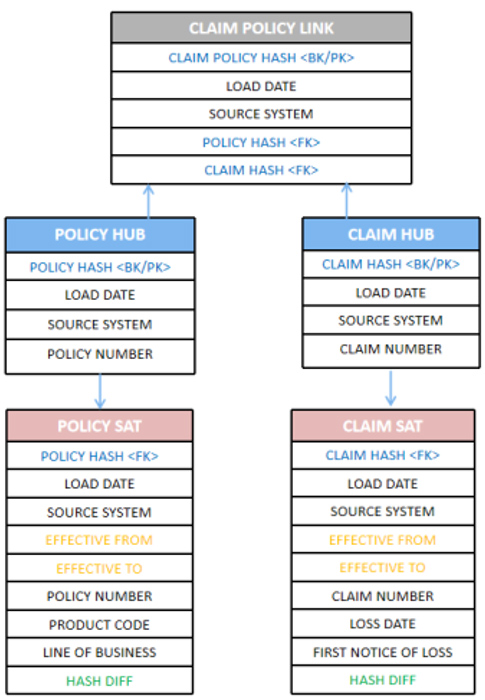
Hubs: Hubs are core entities in Data Vault 2.0. They represent the business concepts or objects that need to be stored and tracked. Hubs contain unique business keys and metadata but do not have any descriptive attributes. Hubs are business driven and are focused on business capabilities.
Links: Links establish relationships between Hubs. They represent the associations between different business objects. Links contain Foreign Keys to the participating hubs and can also include descriptive attributes. In order to accommodate any changes in cardinality or business rules, links are designed as many-to-many structures.
Satellites: Satellites hold descriptive attributes for Hubs and Links. They store historical changes and provide additional context to the core entities. Satellites are time-variant and can be used to track changes over time. It also provides traceability and audibility to multiple source systems.
Business Keys (BK) are fundamental concepts for uniquely identifying and connecting business entities within a Data Warehouse. It is created by hashing (MD5 or SHA) the natural key of the hub. Business keys serve the purpose of a Primary Key (PK) for the hub tables.
This also means we can populate the hub, link, and satellite table with Business Key values in parallel without needing dependency between these three.
Effective from and Effective to dates are for point-in-time information in Satellites, which is used for implementing slowly changing dimensions (type 1 or 2).
Hash Diff helps to detect a change in the table when we receive incremental data. This is created by concatenating all the fields of the satellite table and hashing them using the MD5 or SHA algorithm.
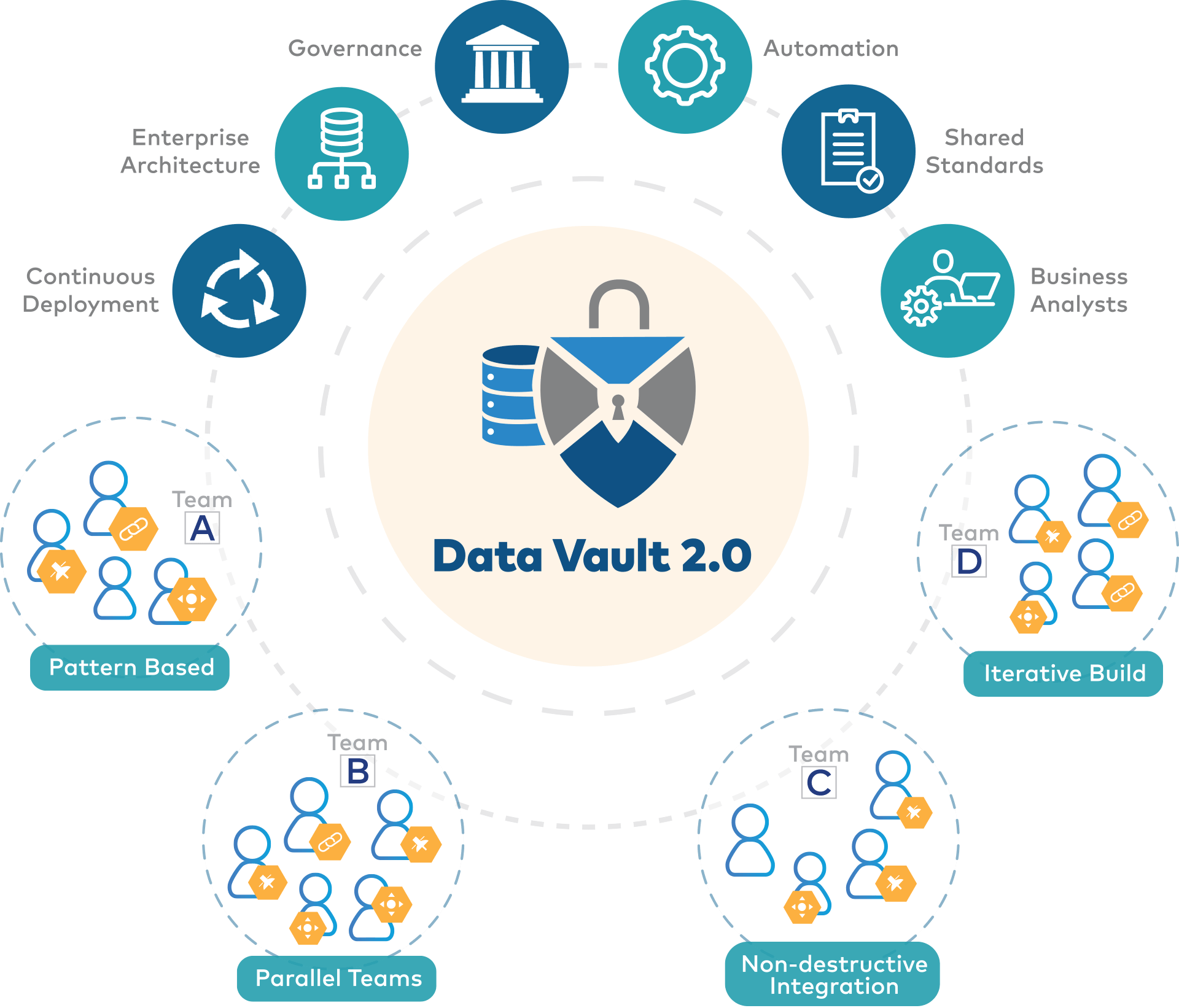
Scalability: While onboarding new source systems, the hub-and-satellite architecture allows for easy scalability by adding new hubs, links, and satellites without disrupting existing structures.
Flexibility: The flexibility of Data Vault lies in its adaptability to changing business requirements. Its design separates business keys from descriptive attributes, allowing for easy integration of new data sources, modifications to existing structures, and agile development processes.
Reduced Time to Market: Data Vault enables quicker data loading simply because several tables can be loaded simultaneously in parallel, which decreases dependencies between tables and simplifies the ingestion process. Data Vault allows for faster development and delivery cycles. Its modular approach enables parallel development, where different teams can work independently on separate areas of the data model, reducing bottlenecks and accelerating time to market.
Conclusion
Data Vault 2.0 has emerged as a game-changing approach to data warehousing, revolutionizing how organizations store, integrate, and analyze data. With its scalability, flexibility, and agility Data Vault 2.0 provides a solid foundation for building modern data ecosystems that can adapt to the evolving needs of businesses. As the volume and complexity of data continue to grow, Data Vault 2.0 stands as a reliable solution to unlock the actual value of data and drive data-driven decision-making.
Some challenges like complexity and time for implementation are addressed by Astraa’s proprietary Metadata Driven framework using Smart Meta Engine.
